
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 코테
- SparkSQL
- 빅쿼리 튜닝
- airflow
- 데이터 시각화
- pyspark오류
- 도커exec
- 시각화
- spark #스파크
- tableau
- PySpark
- 빅쿼리
- 데이터엔지니어링
- docker
- BigQuery
- 프로그래머스 파이썬
- spark explode
- 로컬 pyspark
- dataframe
- spark df
- Big Query
- 도커오류
- sparkdf
- ifkakao2020
- DataFrame Spark
- 태블로
- 언어모델
- LLM
- Docker error
- 도커
- Today
- Total
SOGM'S Data
[NDC 2019] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산 처리 자동화 인프라 구축 _ 내용정리 본문
[NDC 2019] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산 처리 자동화 인프라 구축 _ 내용정리
왈왈가부 2021. 8. 22. 19:42우연히 NDC2019에서 발견한 데브시스터즈의 박주홍님이 발표해주신 Spark, Airflow 관련 엔지니어링 발표한 내용을 정리해보았습니다.
1. 서론
-데이터가 많아지면 ? 메모리와 디스크 부하!
-데이터 엔지니어링은 데이터의 부하 분산이 핵심
2. 본론
-spark란? 분산처리엔진

- 강의의 핵심사진
Driver가 master의 역할, Executor가 분산처리를 수행

1. flintrock 도입
AS-IS 와 문제점:

어떠한 분석 요청이 와서 해당 분석을하기 위해 aws에 spark를 1대 띄우는데 드는 시간이 3분이라하면
(물론 돈이 많다면 항상 spark를 띄어놓겠지만 현실적인 비용문제)
오늘 접속한 유저의 정보를 탐색하는데는 2대가 필요하는데 6분이걸린다. 하지만
지난 주의 접속한 유저 정보를 분석 위해서라면? 14대가 필요하고 띄우는데 6*7(일주일) =42분이 걸리게되는 문제 발생
클러스터를 ASYNC하게 빨리 띄울 수 없을까? ==> flintrock 도입
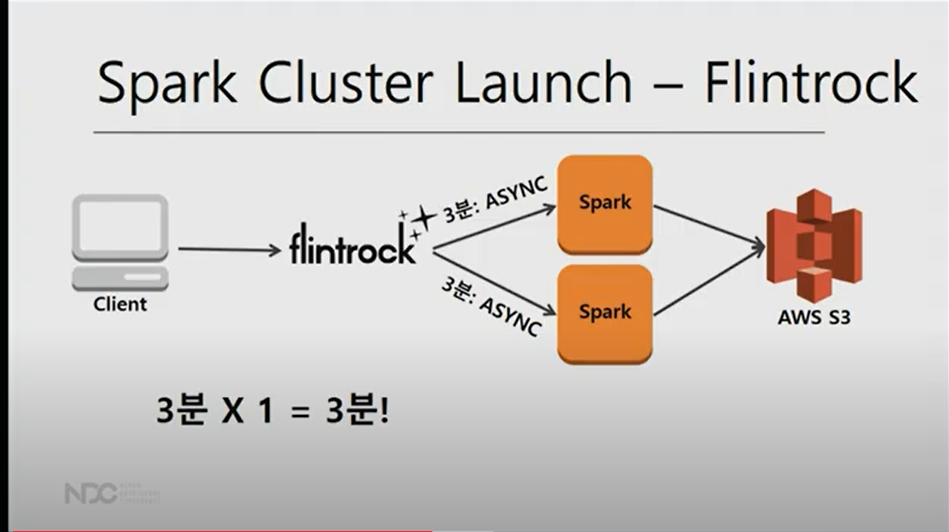
flintrock으로 2대를 띄우면서 단 3분만 걸림. 14대의 서버를 띄우더라도 똑같이 3분걸림(실제로는 async하게 띄우는 과정에서 각종 overhead로 5~7분정도 소요)
TO-BE

그런데 만약 최근 2주동안의 모든 유저의 정보를 보고 싶다면?
아래와 같이하면 될까?

대답은 NOPE!
대신 flintrock의 add,remove slave 기능을 활용
클러스터를 추가, 제거는 간단한 CLI으로 구현할 수 있다.

즉, flintrock 도입의 효과

2. AIRFLOW를 통한 유연한 분석 스케줄링
사업팀 요청 "매일 아침 국가별 매출액을 리포트해주세요"

이 과정을 매일아침마다 리포트를 생성했음. -> 리포트를 매일 아침 해야할까?
AS-IS :CRON
기존에는 CRON이라는 잡스케줄러로 작업을 했었음.

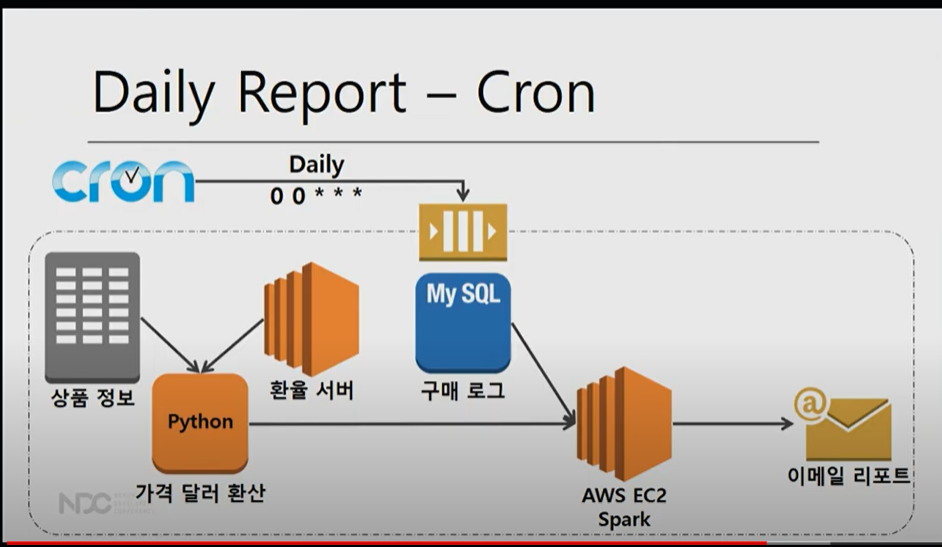
하지만 여러 실패가 나는 경우가 있음.
1. 환율 서버가 API 호출이 실패하는 경우나 2.구매로그를 가져올때 실패하거나 3.리포팅이 실패했을때 실패했다는 메시지를 남기는 것 등
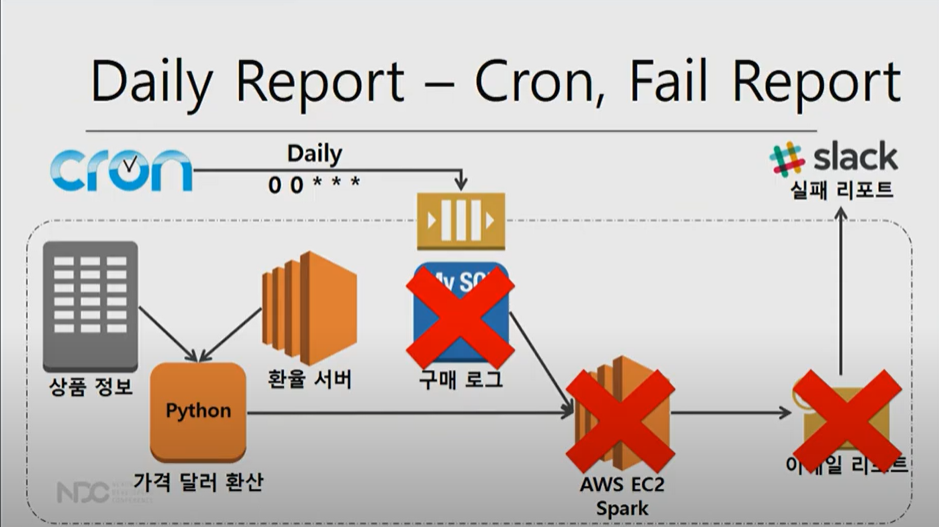
즉 분석 스케줄링에 필요한 기능은 아래와 같다.

CRON의 기능 같은 경우는 주기적 분석 만 가능하고 Retry로직과 failback 및 fail 리포트로직 기능이 없음
TO-BE : AIRFLOW
AIRFOLW는 위에 설명한 3가지 기능 뿐만 아니라 '유연한 분석 의존 관계 관리 (AKA. DAG)' 가능

*맨 첫 번째 DAG인 example_bash_operator의 Schedule 00*** 는 위 CRON의 기능을 DAG로서 관리한것이다.
누가 실행했는지, 어떤 status인지 다 dag로 관리. 실제로 dag를 실제 선택해보면

초록색은 성공 , 분홍색은 skip, 빨간색은 실패를 의미함.
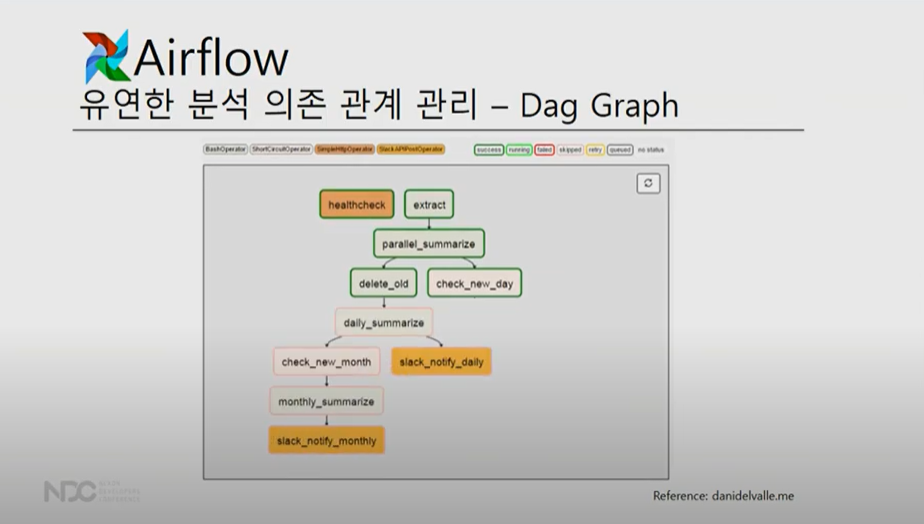
또 다른 Airflow의 강력한 기능 job control

Task Details는 job의 디테일한 설명을 할 수 있고
실패시 run 선택하면 한 번 더돌림.
오늘은 수동으로 했으면 mark success를 통해 오늘은 job 수행 x
실패시 clear 선택하면 초기화 되고 airflow가 재실행 (예시) 10개의 job이 순서대로 실행되어야하는데 실패하면 clear한다면 downstream하면 아래에 있는 job이 다 초기화 재실행.
정리하자면, Airflow는

Flintrock과 Airflow를 활용하여 데이터 분석 요청을 어떻게 수행하는지 본다면,
아래와 같은 요청이 들어왔다면

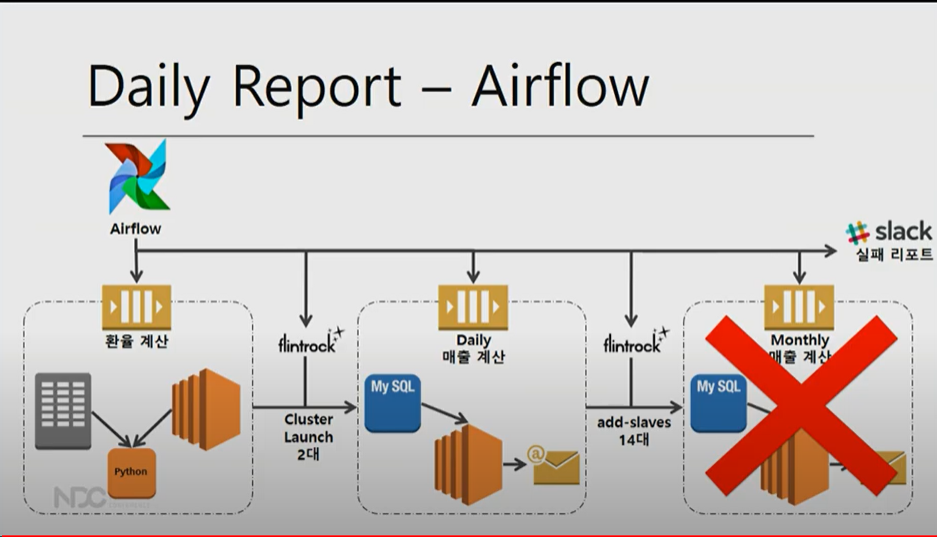
1.우선 Airflow로 서버1대로 돌 수 있는 환율 계산
2. flintrock으로 클러스터 서버 2대 만들어달라 요청 ,일별 매출 계산
3.flintrock으로 14대를 추가해서 월별 매출 계산.
4. 실패시 job schedule로 실패 리포트
즉 클러스터를 큰 거를 띄어서 낭비하거나 혹은 아침에 보고 싶은데 계속 잡이 돌아야한다는 등의 부하를 막을 수 있음
최종 데브시스터즈의 데이터 분석 도식화

모든 분석은 airflow로, 클러스터링은 airflow에서 flintorck 요청하여 스파크클러스터 구성. airflow job scheduling을 통해해 job을 수행.
3. 결론

개인적으로 평소 궁금했던 airflow의 job 스케줄링에 대해 짧은 시간안에 개념을 알 수 있고 실제 예시를 통해 어떻게 적용하는지를 알 수 있는 짧으면서도 좋은 강의였습니다. 발표자 박주홍님께 감사합니다~
'About Data > Engineering' 카테고리의 다른 글
| 로컬에 spark 설치후 pyspark 실행 오류 (3) | 2021.12.31 |
|---|---|
| [1-4] SPARK RDD + structured data (0) | 2021.12.28 |
| [1-3]SPARK RDD 세부설명+dataframe (0) | 2021.12.27 |
| [1-2]SPARK의 실시간 배치 (0) | 2021.12.12 |
| [1-1].SPARK 의 개념과 활용 (0) | 2021.11.30 |



