
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- spark #스파크
- 시각화
- 도커exec
- 빅쿼리 튜닝
- pyspark오류
- 언어모델
- DataFrame Spark
- 프로그래머스 파이썬
- 빅쿼리
- 도커오류
- spark df
- docker
- 데이터엔지니어링
- PySpark
- 코테
- airflow
- 로컬 pyspark
- spark explode
- SparkSQL
- 태블로
- tableau
- Docker error
- Big Query
- dataframe
- sparkdf
- 도커
- 데이터 시각화
- BigQuery
- ifkakao2020
- LLM
- Today
- Total
SOGM'S Data
[1-3]SPARK RDD 세부설명+dataframe 본문
* 본 포스트는 SK T아카데미 아파치 스파크 입문 강의를 듣고 요약 정리한 내용입니다.

RDD: spark dataframe으로 잘 안쓰게 되었지만 스팤의 구성요소이다.
스팤 코어에는 rdd가 있음. transformation 하게되면 rdd가 변경함. map-reduce의 map작업.
로그마이닝 예제이다.
파일 읽고 -> 최초 rdd생성
errors라는 에러를 필터링하고 ->새로운 trasform Rdd생성
count() -> rdd action.
foo와 bar가 몇개 들어가 있는지 수 세기.
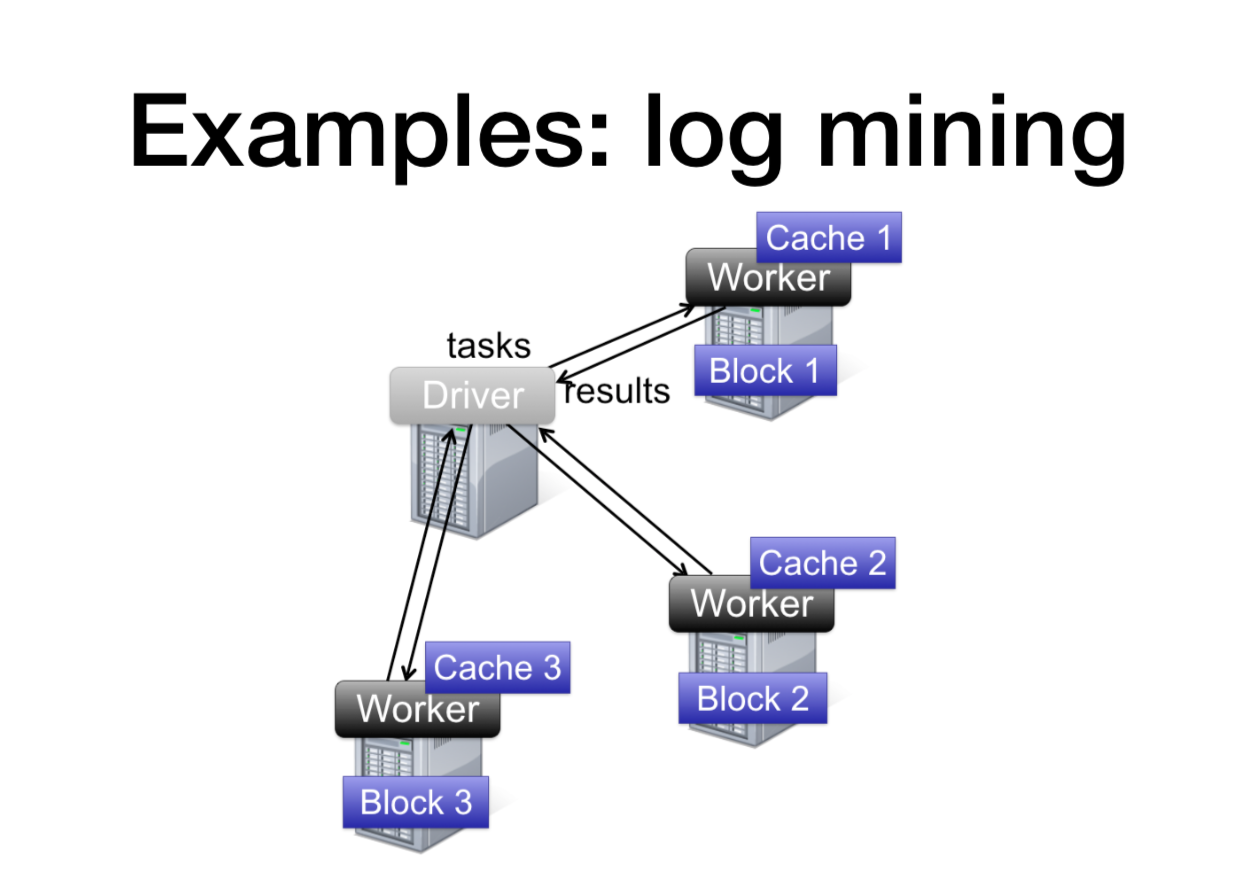
실제 예제의 구조 hdfs파일 블럭단위로 나눠져있고 (블록3개). 실제 spark이 일할때는 action에서만 일함.
드라이버(서버)로 결과를 던져줌
참고로 엔지니어링에서 언어에 대한 참고.
강사님은 분석을 겸업하시는분들은 spark pyspark + 약간의 scala를 추천하셨습니다.

분석가들도 Scala 언어에 관심이 있다면 배울 필요가 있다. 필수는 아니다.!!

간단한 scala 공부


Spark의 transformation , action 설명
action이 발생했을 때만 스파크 대시보드 dag 에 표시.
아래 구조를 보면 더 명확히 위에서 설명한 것들이 나온다 (개인적으로는 가장 스팍의 기본원리와 장점을 잘 설명해주는 그림)
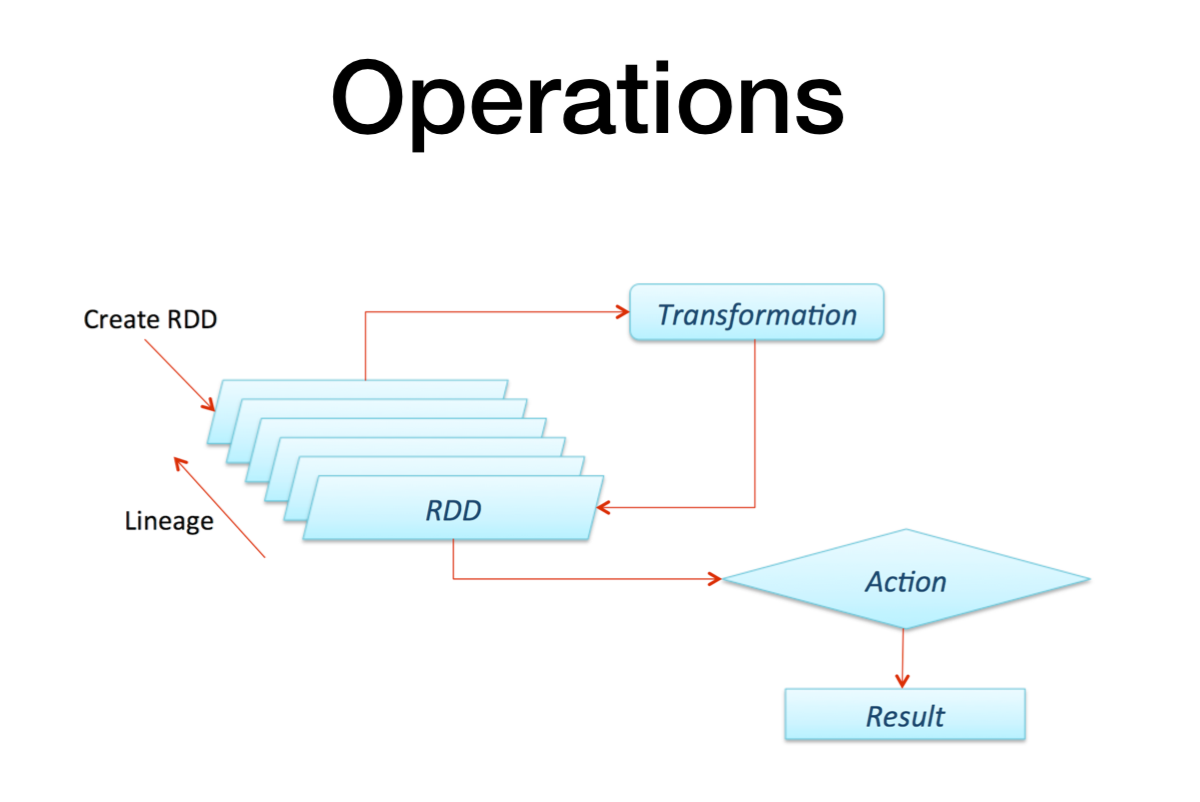
데이터를 바꾸고 groupby하고 type을 지정할때마다 (=transformation) 그 rdd가 생성되고 그 rdd들의 대해 Lineage한 트랙킹을 제공함.
특정 transformation에서 문제가 생겼을때 덕분에 문제가 생긴 이전 rdd에서 recompute하여 fault tolerance 가 가능케 함.
실제 action이 발생시 result를 서버로 전달해주거나 외부 external 시스템에 저장하거나 etc...
세부 transformation과 세부 action에 대해 알아보자
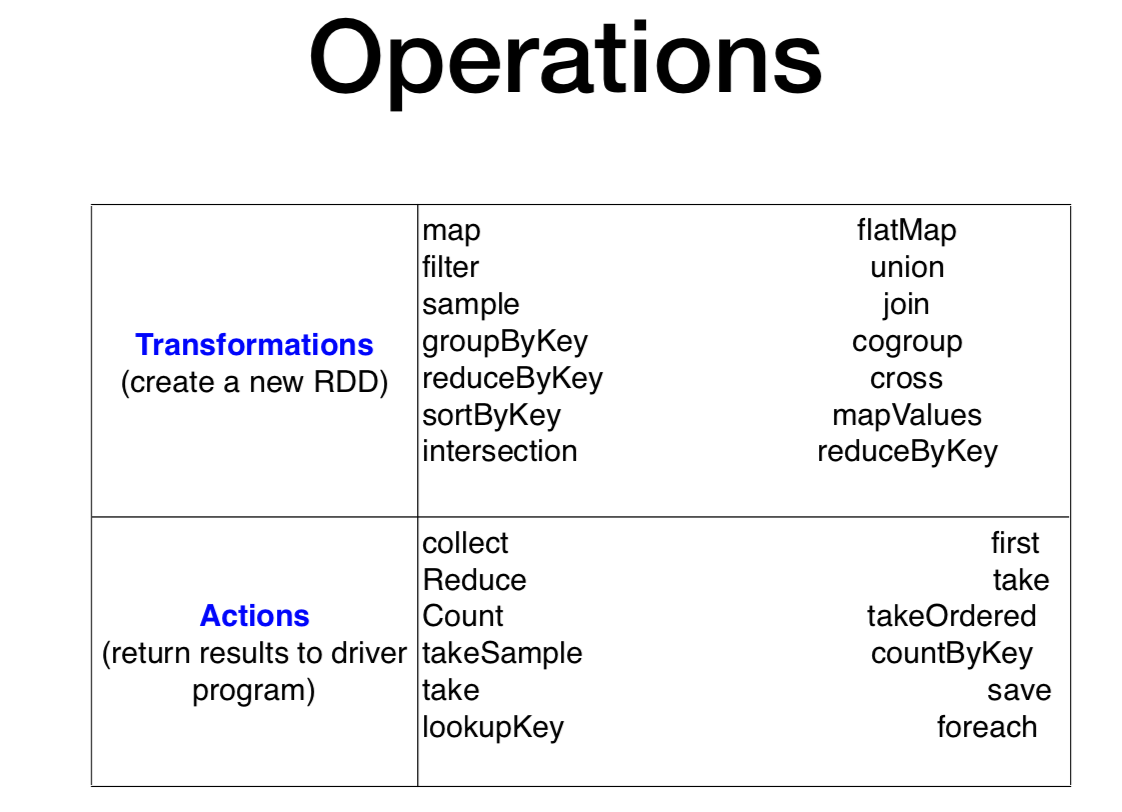
rdd vs dataframe 차이
* dataframe쓸 경우 scala나 python이나 큰 차이 없음.
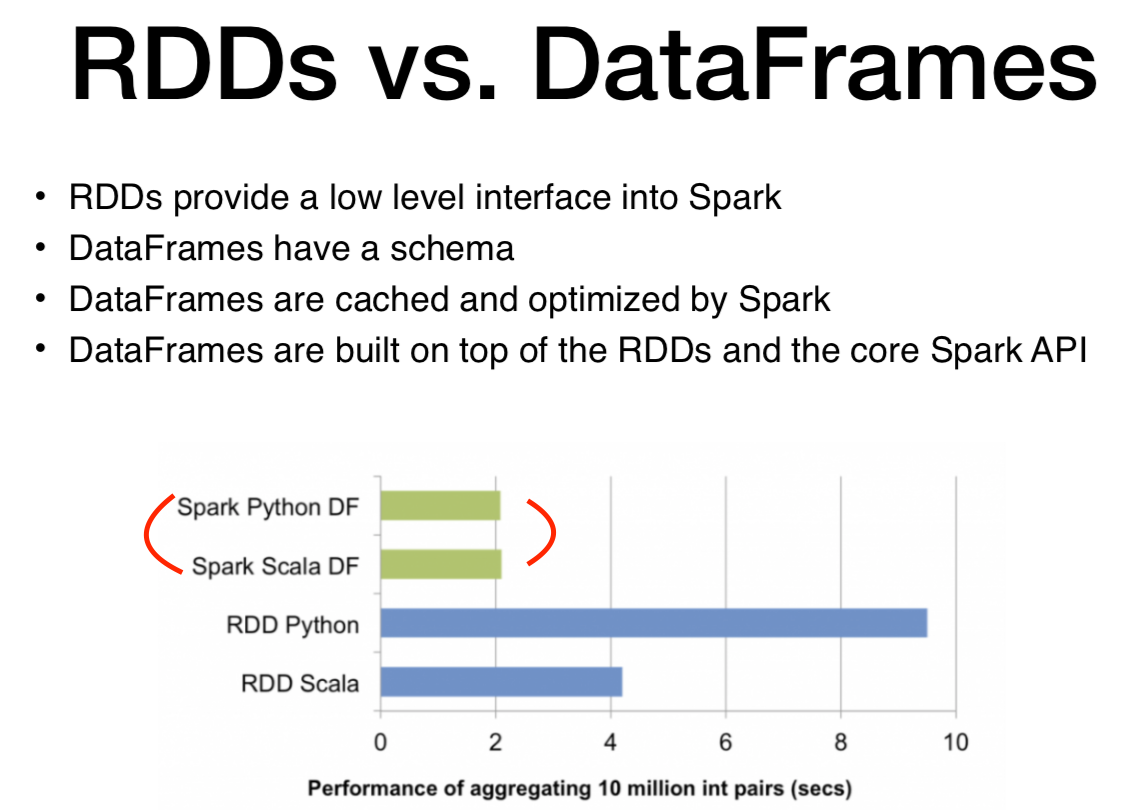
dataframe은 어떨까?! 스키마를 이미 가지고 있기 때문에 간결하며 기존 python 문법이랑 비슷하다.

'About Data > Engineering' 카테고리의 다른 글
| 로컬에 spark 설치후 pyspark 실행 오류 (3) | 2021.12.31 |
|---|---|
| [1-4] SPARK RDD + structured data (0) | 2021.12.28 |
| [1-2]SPARK의 실시간 배치 (0) | 2021.12.12 |
| [1-1].SPARK 의 개념과 활용 (0) | 2021.11.30 |
| [NDC 2019] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산 처리 자동화 인프라 구축 _ 내용정리 (0) | 2021.08.22 |



