
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
- tableau
- 시각화
- PySpark
- DataFrame Spark
- BigQuery
- docker
- spark explode
- airflow
- 빅쿼리 튜닝
- LLM
- 프로그래머스 파이썬
- pyspark오류
- 로컬 pyspark
- 빅쿼리
- ifkakao2020
- SparkSQL
- Big Query
- 데이터 시각화
- 태블로
- 도커exec
- Docker error
- spark df
- 코테
- 도커
- dataframe
- spark #스파크
- sparkdf
- 데이터엔지니어링
- 언어모델
- 도커오류
- Today
- Total
SOGM'S Data
[1-4] SPARK RDD + structured data 본문
* 본 포스트는 SK T아카데미 아파치 스파크 입문 강의를 듣고 요약 정리한 내용입니다.
Directed Acyclic Graph(DAG) dag 는 lineage라고 보면됨.

각각의node들은 데이터를 transform할때마다 생기는 rdd


n개의 스테이지에서 m개의 태스크로 나뉘는 모습.
스테이지를 구분은 transformation은 같은 stage 로 묶임.
reduce , shuffle , join의 경우 다른 stage로 구분됨.
태스크를 나누는 구분은 executer의 개수와 관련이 있다. 가용한 executer가 100개면 100개의 태스크로 나뉨.
transformation - narrow vs wide


Action은 마지막 단계 . dag가 시행되는 구간임.
collect , count , show, write, external 로 보내는 것에만 dag작동. 다시 강조하지만 spark은 action단계에서만 일한다.


Rdd persistence -> cache 와 동일레벨
memory only가 default.
<복습>
<문제>

복습 !! 빈 칸에 알맞은 말을 넣어보시오 (드래그로 아래 답변확인)
<답변>
1. transformaion , action
2. lazy (= not compute immediately)
3.run ( transformation은 액션이 Run할때 실행한다.)
4. rdd의 경우 persist , dataframe의 경우 cache
<문제>

각 블록에 errro, ts msg, warn,info.. 가 담겨있는데 람다 필터를 통해 각 블럭으 error만을 가져온다. (=errorsrdd생성)

2번째 블록에서는 error가 없음. rdd의 파티션을 4->2개로 줄임
파티션을 줄이는 법은 repartition과 coalesce 가 있음
repartition은 전부 sorting 한 뒤 줄이고, coalesce는 저상태에서 그냥 파티션 줄임.
몇 백만건 들어간 블럭, 하나 들어간 블럭 이런식으로 실제로 블럭이 차이가 나는데 한 블럭이 끝날때 까지 작업이 안돌기 때문에
리파티셔닝이 필요.
4->2개로 Cleandrdd생성후 driver로 collect.

collect 말고 s3저장, count 등등 다양한 action을 하는데 만약 cleanedrdd가 캐시되어 있지 않으면 base rdd부터 다시 데이터 접근 시작해야 함. 매번 원천로그를 읽을 필요없다!
캐시는 스파크가 자동으로 해주는 것이아닌 작업자가 명시적으로 해야함.

드래그 후 답 확인!
.job(action 이 발생할때 )
2. stage(transformation들)
3. task(스테이지 안에 있는 작업 . 실습에서는 제플린이라 task가 하나지만 클러스터환경에서는 여러 task가 존재)
4.shuffle

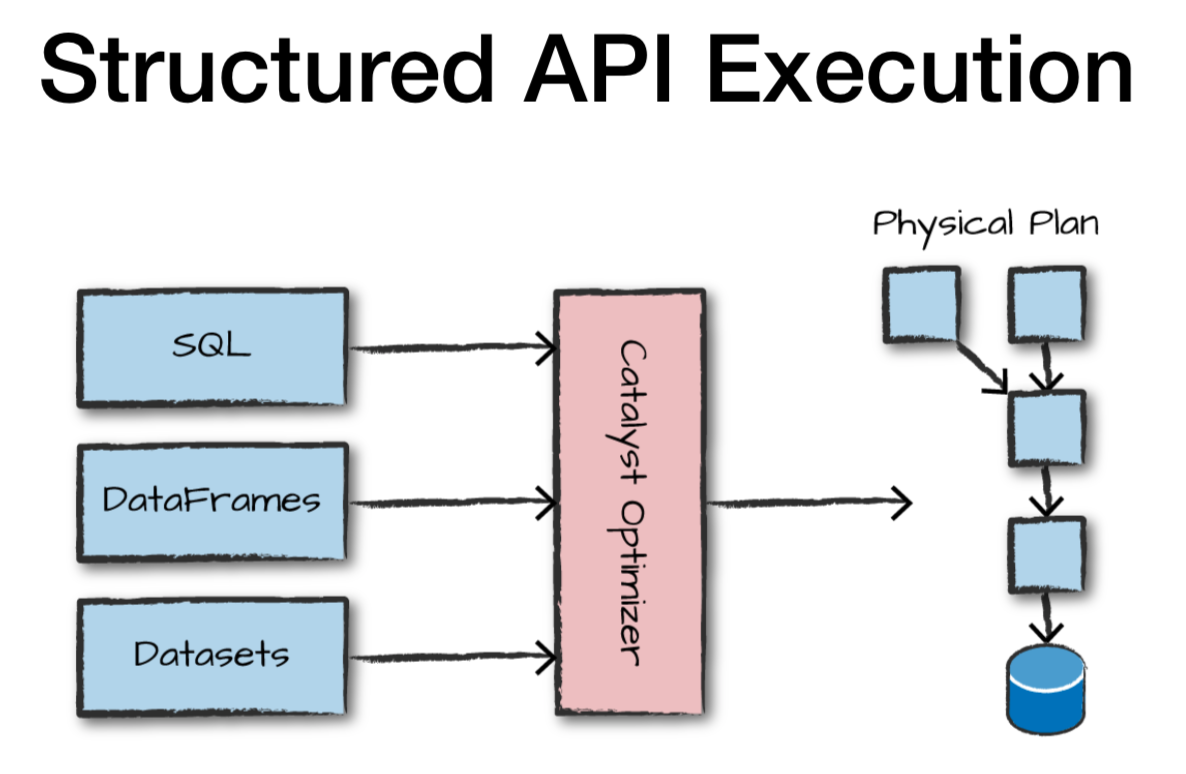
catalyst optimaizer : 실행계획 관장하여 실제 dag가 수행되는지 최적화 역할.


catalyst optimaizer 이 logical planning -> physical planning을 통해 최적의 dag를 만들게 됨.
->dataframe을 사용하게되면 특정언어를 상관없이 동등한 성능을 보일 수 있는 이유.
데이터프레임:

Df연결 : jdbc연결 users df가져옴
hadoop에 있는 기존 traffic log를 가져와서 join 하는 예제.

데이터프레임 input output 제공 목록들.
optimizer 예시
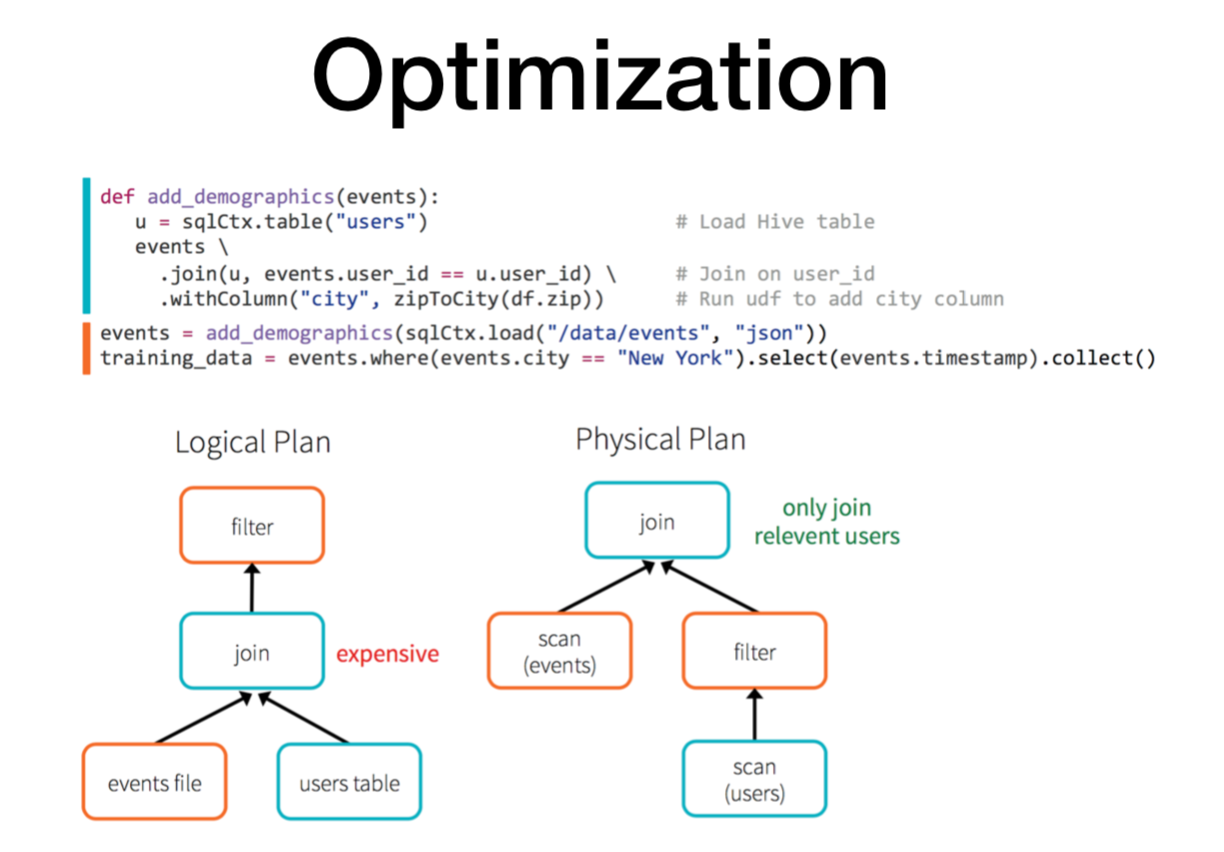
논리적 계획에서는 '비싸네'를 인지
물리적 계획에서는 '필터를 씌워서 관련있는 로그들만 가져와서 조인하자'

partition 된 것들만 불러와서 i/o를 줄인다.
데이터프레임 다루기(코드 글씨 작아서 이미지 확대)

피벗팅 예제1

피벗팅 예제2

피벗팅 예제3. feature generation
coalesce(first(rating)3) -> null일때 평점 3준다는 뜻.
'About Data > Engineering' 카테고리의 다른 글
| SPARK_01 : RDD_1 (0) | 2022.01.11 |
|---|---|
| 로컬에 spark 설치후 pyspark 실행 오류 (3) | 2021.12.31 |
| [1-3]SPARK RDD 세부설명+dataframe (0) | 2021.12.27 |
| [1-2]SPARK의 실시간 배치 (0) | 2021.12.12 |
| [1-1].SPARK 의 개념과 활용 (0) | 2021.11.30 |



