
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- pyspark오류
- LLM
- 데이터엔지니어링
- airflow
- 빅쿼리
- 코테
- 데이터 시각화
- spark #스파크
- spark explode
- Docker error
- 태블로
- spark df
- 도커오류
- BigQuery
- 도커
- 빅쿼리 튜닝
- DataFrame Spark
- dataframe
- tableau
- 언어모델
- 로컬 pyspark
- Big Query
- PySpark
- sparkdf
- 프로그래머스 파이썬
- ifkakao2020
- docker
- SparkSQL
- 시각화
- 도커exec
- Today
- Total
SOGM'S Data
[1-2]SPARK의 실시간 배치 본문
* 본 포스트는 SK T아카데미 아파치 스파크 입문 강의를 듣고 요약 정리한 내용입니다.
<빅데이터 프로세스>
1부 --- 부제: 빅데이터 프로세스 - 실시간 데이터를 위하여~

빅데이터 프로세싱 3가지.
스파크 프로세스는 3번째 micro batch라고 생각하면됨. batch와 stream과의 중간. (아주작은 배치단위로 처리)
인스트림 (=네이티브스트림 )방식
source opertor : n개 동작, 데이터 수집 ex.카프카
sink operater: ex/엘라스틱서치
스파크 스트리밍의 마이크로 배치 예시
receiver나 sinkoperator는 카프가 등등 쓰이는 것은 똑같고
두 가지 차이는 앞단에 마이크로 배치로 데이터를 가지고와서 처리하는지 유무로 나뉨.
Stream Processing Framework 종류
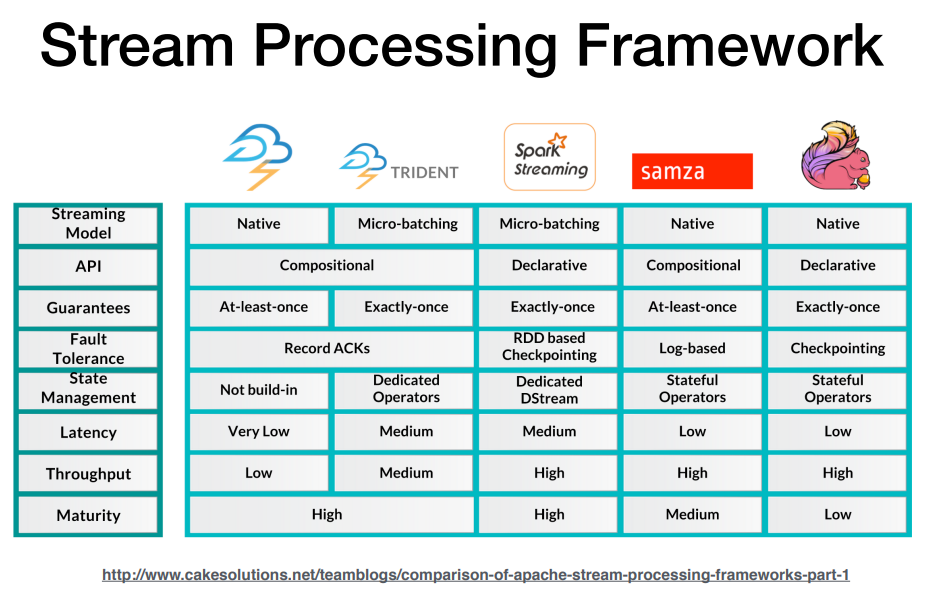
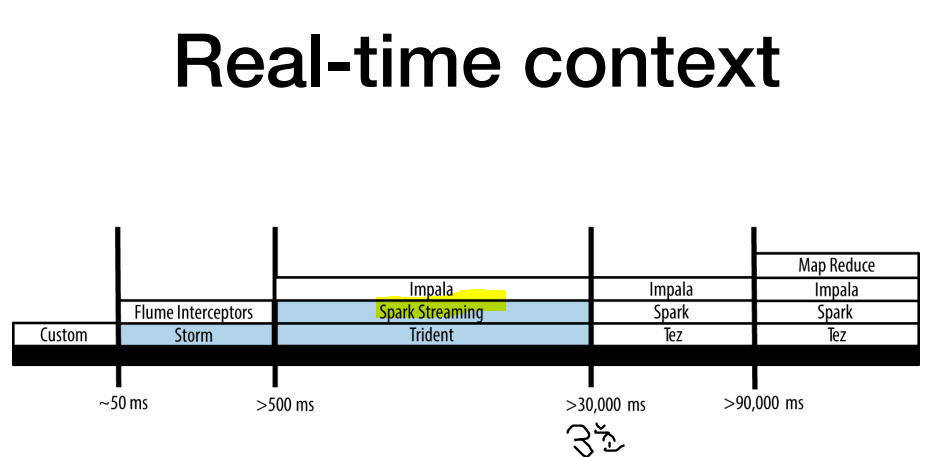
spark streaming은 약 3초 strom과 flink와 달리 latency 발생
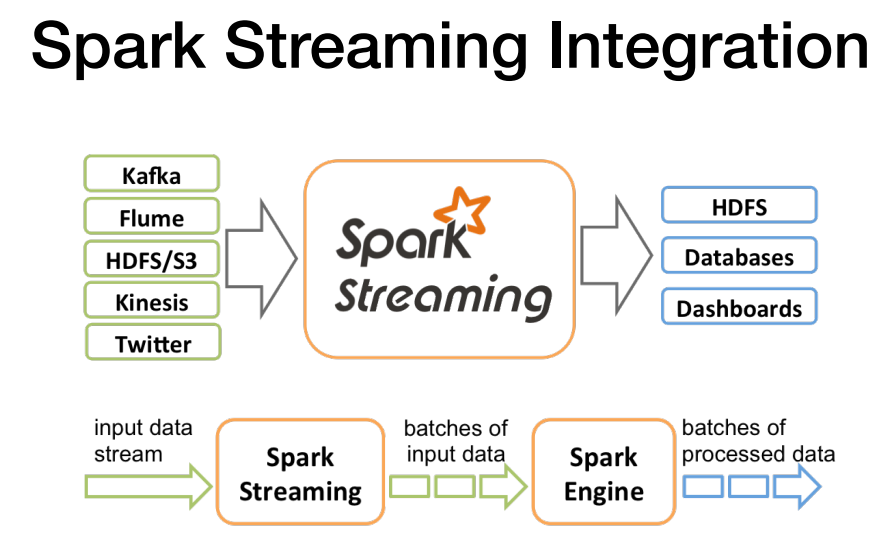
스파크 스트리밍 integration에서는 생태계가 다음과 같다.
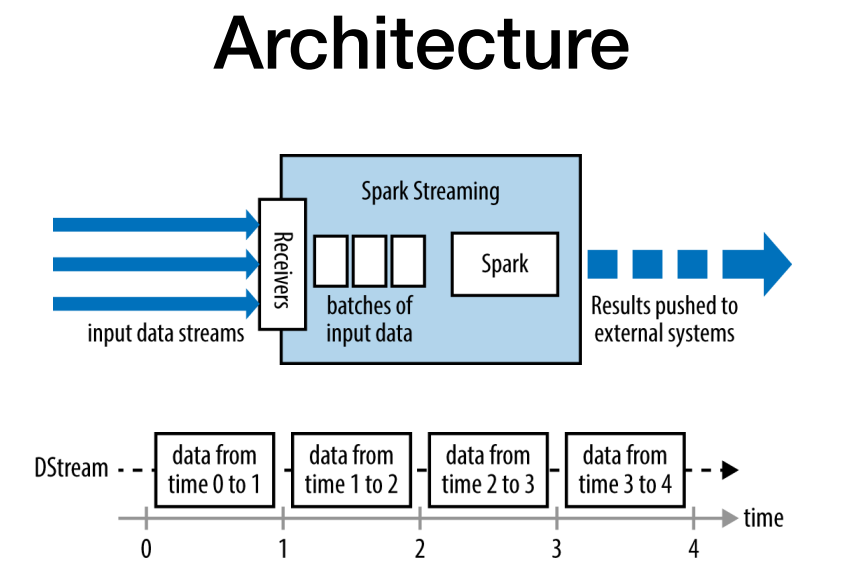
배치사이즈로 스파크스트리밍에 의해 쪼개지며 (ex 10초) , 스파크 엔진이 배치 프로세스에따라 데이터 처리.
스파크 스트리밍 RDD 프로그래밍 예시

스파크 스트리밍은 개발은 어렵지 않나 운영중 트러블이나 장애가 많이 발생 SPARK UI에서 대시보드로 스트리밍이 잘 작동되는지 확인할 수 있다.
스파크 Dstream
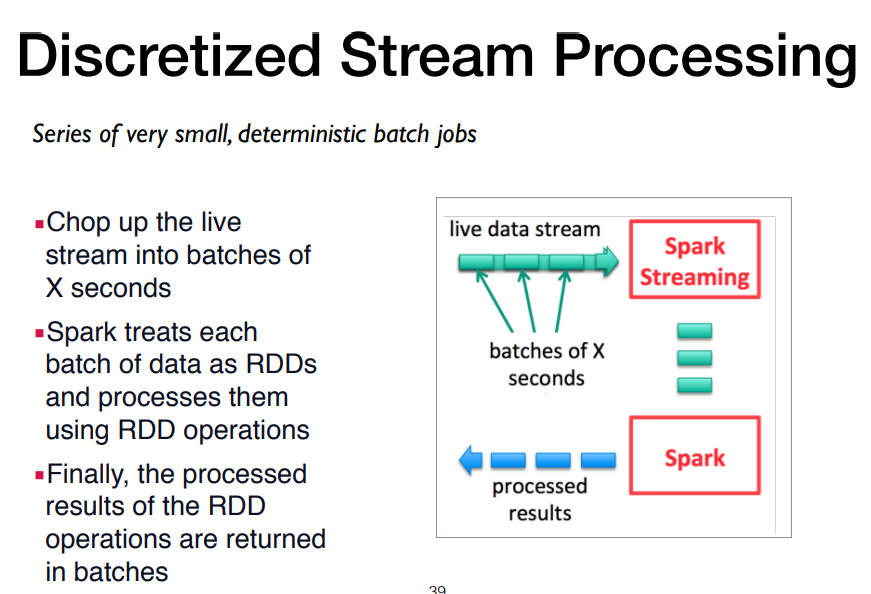
예시) 트위터 해쉬태그 카운팅하는 예시 ex/ 반응률
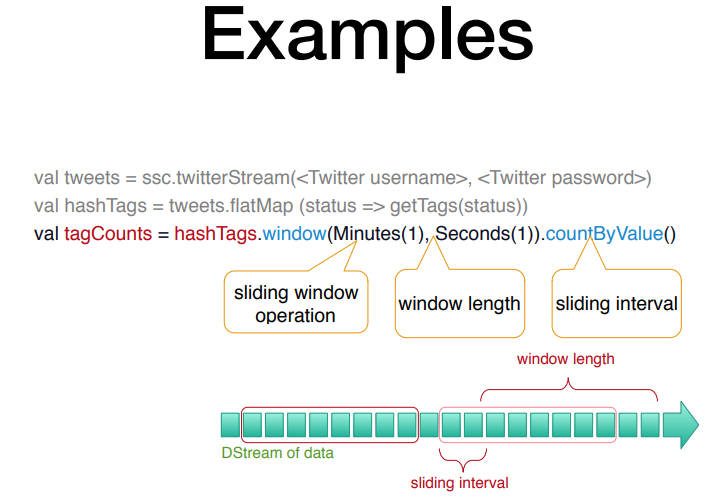
1초단위로 데이터를 가져오고 time window 1분단위로 value를 연산
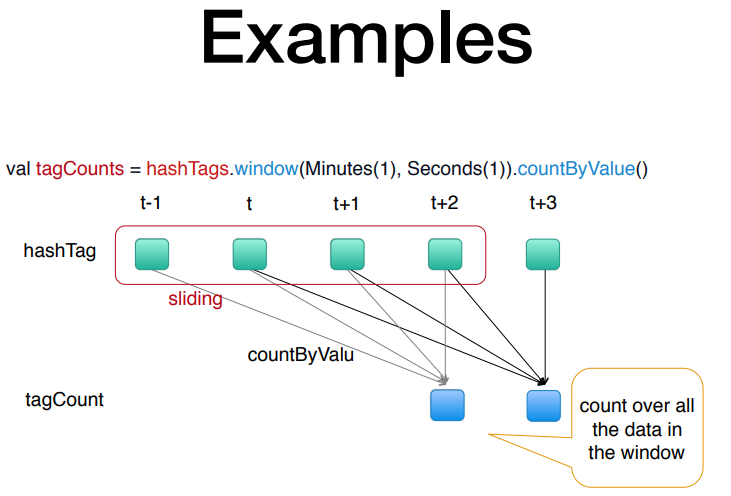
초단위로 슬라이딩 되면서 계산되는 모습.
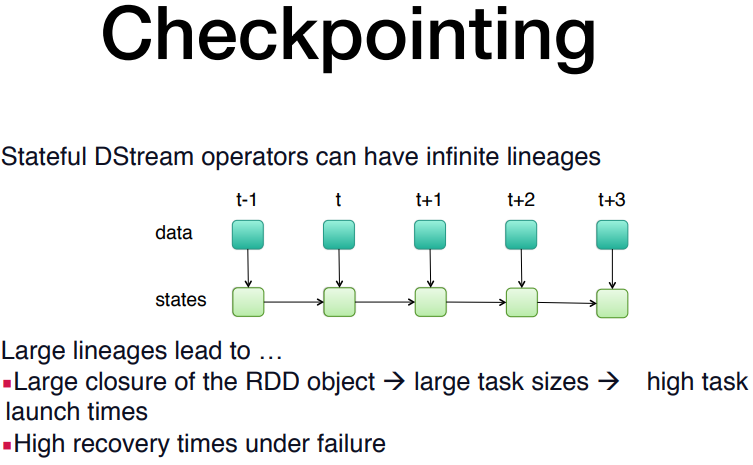
checkpointing 체크포인팅:
Q) in-momory로 처리할시 문제가 생기면 재연산을 어떻게하지?
-> 스파크스트리밍의경우 각각의 RDD가 생성되면서 chaeckpointing을 통해 상태를 저장.
단, 상태를 저장하다보니 그 양이 많아져버리면 다시 re-launch할때 수행시간이 오래걸리기때문에, 적절한 checkpointing이 필요함.
Accumulator 와 Broadingcast

Accumulator . 스파크스트리밍의 디버깅용. 운영단에서는 실제로 쓰진않음. Accuulator가 메모리를 먹기때문

Broadcast . 매번 조인하지만, 매번 읽는 것이 아닌 한번 로딩해놓는 경우 활용.
그러나 스파크 스트리밍에서는 개인적으로 지양하는 거 추천하심.

아키텍쳐면에서 고려해야할 점

예시) 기지국 데이터처럼 갑자기 데이터가 갑자기 폭증할수 있기 때문에 scalability도 고려되어 설계되어야함.
fail된 작업을 어떻게 할 것인가.
그렇다면 실시간 스트리밍은 어디에 쓰일까? (USE-CASE)

DBMS와는 다름. 대시보드는 별도로 엘라스틱서치에서 빠르게 시각화 처리.
알람이나 제조라인에서도 쓰일 수 있음.
SPARK STREAMING의 퍼포먼스 튜닝

배치사이즈에 대한 고민. 윈도우 계산 사이즈. (0.5초 유지 권장 )
배치사이즈를 10초에서 점차 줄여감. BOTTLENECK확인.
예시) 기지국 개수가 늘어나며 데이터가 늘어나서 쉬도때도 없이 드라이버 재시작함.
병렬성에 대한 고려
예시) 카프카의 경우 Repartition하여 병렬성을 높임.
리파티션이란? 파티션 10개 -> 파티션 100개로 쪼개서 실시간으로 100개로 처리될 수 있도록 작업을 나누는것.
*리파티션되면 전체 데이터가 suffling됨으로 주의해야함. GroupByKey()와 달리 reduceByKey() 는 키가 sufflin되지 않아 좋음.
항상 지연없이 보기 위해서는 중요함.
스파크 스트리밍은 jvm 모니터링하여 실제 어디서 병목발생하는지 확인 필수 !!
카프카에대해 알아보자
카프카는 분산메시징 서버다.
메시지의 카테고리를 토픽으로 관리하고 각각의 토픽은 n개의 파티션으로 구성 (하둡이랑 비슷)
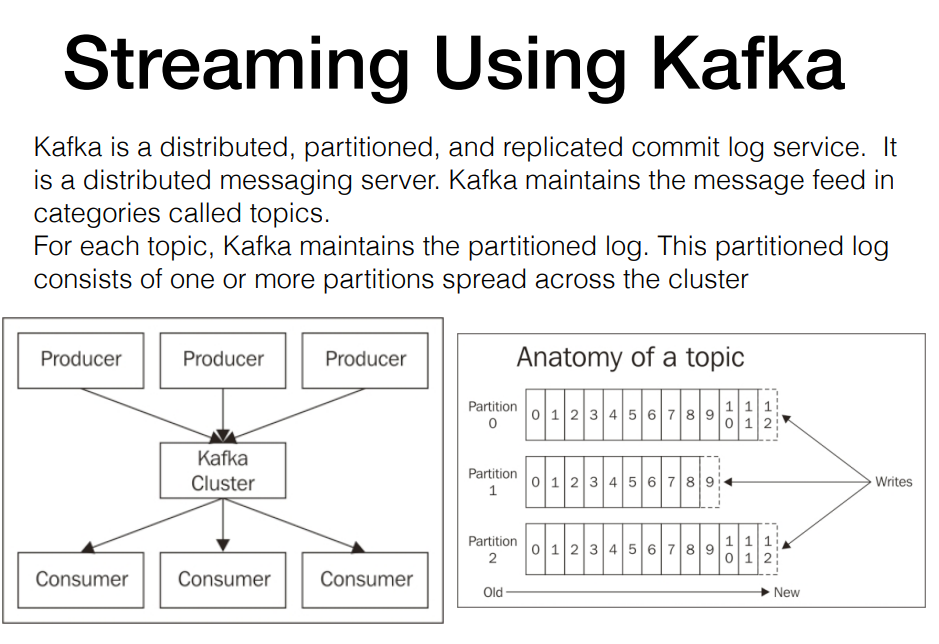
consumer그룹을 여러개 둬서 데이터에 대한 재가공이 가능함.
consumer1 (1~10까지 읽었어요) , consumer2(1~20까지 읽었어요) 등
그럼여기서 스파크에서 어떻게 처리할까 (RDD옛날 코드 유념)
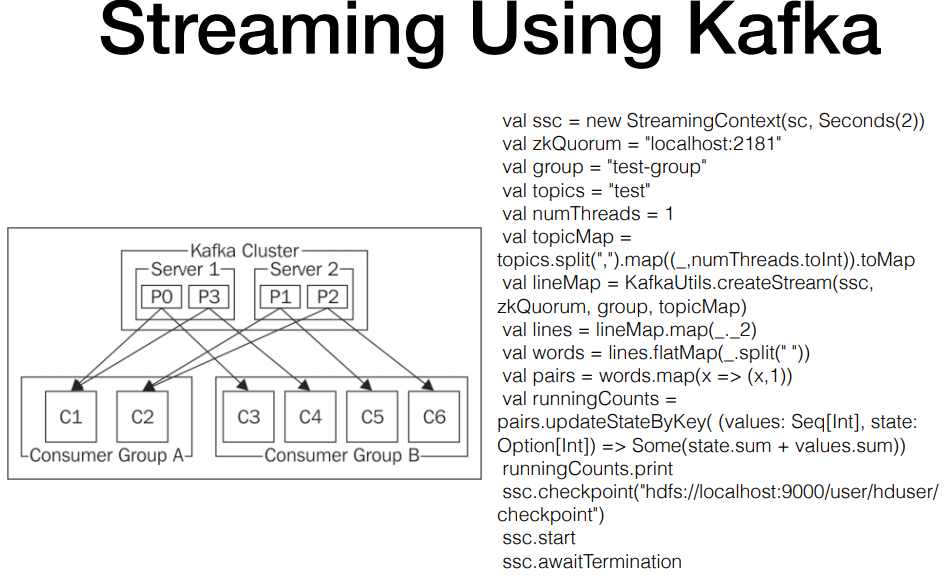
파티션 별로 어떤 offset까지 읽었고, 다음부턴 어디서 부터읽겠다 지정 가능.
스파크 스트리밍은 구현,개발은 쉬우나, 운영이 어려움.
2부 --- 부제: 2.0 DF와 API로 모두가 쉽게 , 편하게 스트리밍
SPARK 2.0 : Structured Streaming
스파크 스트리밍은 rdd기반이지만 , dataframe 기반으로 처리가 가능하게 되어짐.
우리가 실제로 다루는 데이터가 대부분 스펙이 json이라 스키마를 이미 가지고 있어서 바로 스키마 로딩하여 데이터 엑세스하는 방식.
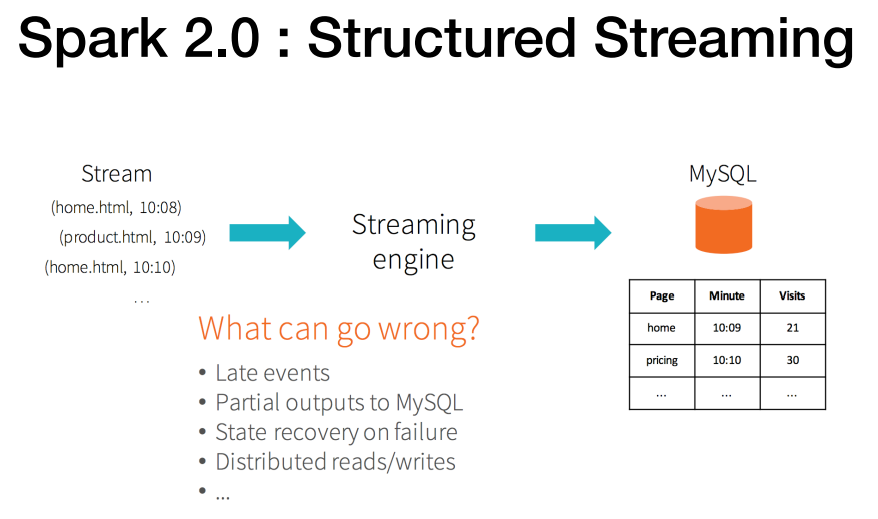

dataframe처럼 쿼리를 바로 넣을 수 있음. HIGHLEVEL API로 전부 지원.
ex. kafka 소스에서 읽을지, mysql로 저장할거야 이런 것들이 코드로 구현이 아닌 API로 지정만해주면 됨.
-데이터 JDBC 바로 꽂을 수 있음.
-쿼리 바꿀 수 있음. ML 실시간 서비스도 가능.
이 모든 것들이 데이터프레임이 지원되기 때문임.
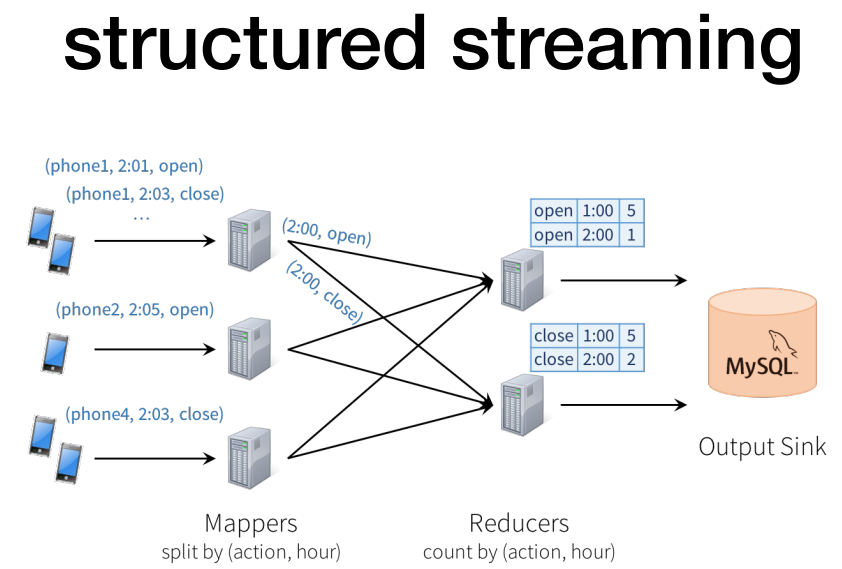
수도코드 예시 (페이지 뷰 카운트)

위 해석: Kafka에서 데이터를 읽고, 페이지 그룹별로 1분당 카운트로 구하고 이것을 5초마다 실행.
이것이 mysql로 데이터 들어가야함.
(아래는 kafka대신 json , mysql 대신 JDBC 대체)
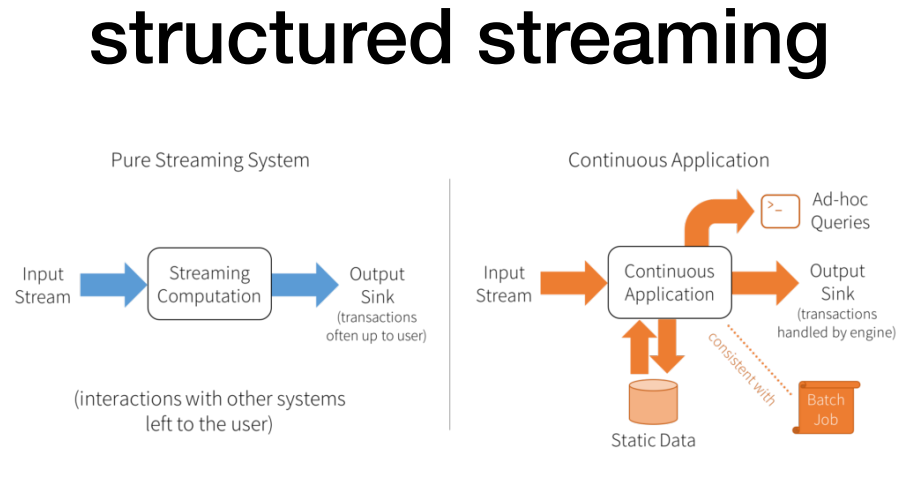
우측의 경우 아웃풋 싱크에서 트랜젝션까지 지원.
dstream에서는 불가능했던 eventtime에 대한 stream processing.
입수된 시간 기준이 아니라, 실제 데이터가 유입된 이벤트 타입별로 연산이 가능해짐.

워터마킹 : late메시지.
늦은 데이터들을 기다려주는 형태. 15분까지 기다려줌.

예제) static 데이터를 가져올 수 있음.
kafka에서 'iot-updata'라는 토픽를 땡겨옴. join도 가능함. 특정 서비스(mysql)등으로 sink가능

output 모드

각각 쿼리 management도 가능함.

Q. gkenq
'About Data > Engineering' 카테고리의 다른 글
| 로컬에 spark 설치후 pyspark 실행 오류 (3) | 2021.12.31 |
|---|---|
| [1-4] SPARK RDD + structured data (0) | 2021.12.28 |
| [1-3]SPARK RDD 세부설명+dataframe (0) | 2021.12.27 |
| [1-1].SPARK 의 개념과 활용 (0) | 2021.11.30 |
| [NDC 2019] Spark, Flintrock, Airflow 로 구현하는 탄력적이고 유연한 데이터 분산 처리 자동화 인프라 구축 _ 내용정리 (0) | 2021.08.22 |



