
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 시각화
- sparkdf
- 도커
- 프로그래머스 파이썬
- PySpark
- explode
- ifkakao2020
- 도커exec
- 로컬 pyspark
- 빅쿼리 튜닝
- dataframe
- BigQuery
- 데이터 시각화
- 코테
- docker
- spark #스파크
- 데이터엔지니어링
- 도커오류
- tableau
- Big Query
- Docker error
- 태블로
- spark df
- spark explode
- 비주얼라이제이션
- pyspark오류
- DataFrame Spark
- SparkSQL
- 빅쿼리
- airflow
- Today
- Total
SOGM'S Data
Numpy만 이용하여 SVD 추천시스템을 간단히 실험해보자(Truncated SVD) 본문
Numpy만 이용하여 SVD 추천시스템을 간단히 실험해보자(Truncated SVD)
왈왈가부 2020. 10. 27. 18:07SVD 말로만 들어도 헷갈리는 이론을 한 번 직관적으로 풀어나가보고 싶어나가보겠습니다.
고유값 고유벡터를 배우면서 SVD,PCA와 같은 차원축소에 대해 궁금하신 분들이 많을 것입니다.
이 글을 통해 SVD를 설명하고 간단한 데이터 셋으로 SVD(Truncated 된)를 이용한 추천시스템 구현을 설명하고자합니다.
(단 이 글은 고유값과 고유벡터의 정의와 구하는 방식을 아신다고 가정하고 글을 썼습니다)
SVD란 무엇인가? (Singular Value Decomposition, 특이값 분해)
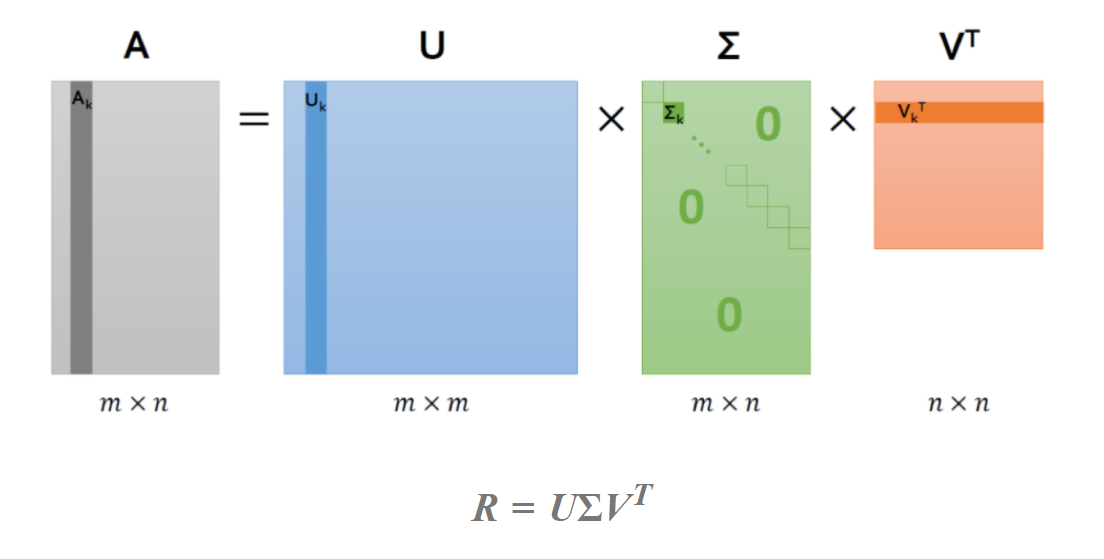
출처:www.fun-coding.org/recommend_basic6.html
데이터 분석(추천시스템): SVD (SVD와 Latent Factor 모형) - 잔재미코딩
$$ r_{ui} = p_u \cdot q_i $$ \begin{array}{ll} \text{Alice} & = 10\% \color{#048BA8}{\text{ Action fan}} &+ 10\% \color{#048BA8}{\text{ Comedy fan}} &+ 50\% \color{#048BA8}{\text{ Romance fan}} &+\cdots\\ \text{Bob} &= 50\% \color{#048BA8}{\text{ Action fa
www.fun-coding.org
말그대로,
행렬 A를 직교행렬 U (A의 고유벡터로 이루어짐) ,V (고유값 대각행렬 ∑) , Vt (A의 고유벡터로 이루어짐)
으로 분해하는 것입니다.
자세한 내용은 아래 15분정도 MIT의 SVD 동영상을 시청하자. 보다 직관적인 이해 가능
www.youtube.com/watch?v=mBcLRGuAFU
SVD를 공부하면서 가장 큰 의문점은
저 같이 선형대수를 접한지 얼마 안된 사람들은 이해가 안될 것입니다. 왜 멀쩡한 행렬을 분해할까?
즉 힘들게 수집한 데이터를 왜 분해할까?
여러 이유가 있지만 가장 큰 이유는 행렬 분해를 통해 특징값을 원하는 만큼 조정할 수 있다는 것입니다.
가장 직관적인 설명이 가능한 이미지 분석 CNN에서 어떻게 행렬 분해가 쓰이는 지 말씀드리겠습니다
(ex, 해상도 100의 인물사진을 행렬 분해 후 80%의 해당되는 상위 고유값을 사용하여 해상도 80의 사진으로 만들 수 있다. 이때 (눈,코,입) 형태는 유지 되기때문에 충분히 모델에서 인식이 가능하고, 오히려 overfitting도 막아준다 )
즉, 1. 데이터의 크기를 줄여줌(속도면에서 유리)
2. 데이터의 overfitting도 완화 해주는 아주 효자같은 녀석입니다.
하지만 해당 포스트의 목적은 추천시스템이므로 추천시스템에서의 SVD의 쓰임을 차근 차근 설명드리겠습니다.
영화를 예시로 들어보겠습니다.
우선 추천시스템 데이터의 가장 기본 모형은 USER-MOVIE 형태의 데이터입니다. 행이 USER, 열이 MOVIE로 되어 있고각각의 VALUE는 RATING 평점으로 이루어져 있죠.
하지만 USER들이 모든 영화를 볼 수 없기 때문에( 혹은 평점을 남기지 않기에) 사용자 평점 행렬들은 필연적으로 sparse한 형태를 가집니다.
이때 SVD는 알려지지 않은 요소 (Latent_Factor)을 통해 행렬을 분해할 수 있습니다 .
USER-MOVIE 의 행렬 A를 U (USER-Latent_Factor), ∑ (Latent_Factor) , Vt (MOVIE-Latent_Factor) 로 나누는 것입니다.
그렇다면 , ∑는 각 Latent Factor의 중요도를 나타내는 데, A의 행렬의 대표적 Latent Factor는 무엇이 있을까요?
정확히 알 수는 없지만 장르, 시청제한연령, 제작년도 등이 있을 것입니다.
그 요소들중 SVD는 특정 요소를 선택하여 (=특이값을 통해) 근사행렬 B를 구할 수 있는 것이죠.
그렇기에 고전적인 추천시스템의 방식중 하나인 SVD를 통한 평점을 도출할 수 있는데 순서는 다음과 같습니다.
※ 손실함수를 통한 SVD구현이 아닌 단순한 (임의의) 방식입니다
첫 째, 본래 행렬 X의 sparse한 값들에 USER i 가 준 다른 영화들의 평균 값을 대입하여 행렬 A를 만든다.
둘 째, sparse한 값들을 채운 행렬에 SVD를 수행한다. (단 이때 특이값의 일부만 사용한다= *Truncated SVD) Truncated SVD로 산출된 U,∑, Vt 를 다시 내적하여 새로운 행렬 B를 구한다.
셋 째, 행렬 A와 B를 비교한다.
*Truncated SVD란 : SVD에서 상위 N만큼의 고유벡터와 고유값을 통해 근사행렬을 구하는 방법입니다.
이제 위 3 과정을 통해 다음과 같이 SVD를 통한 추천시스템을 구현해보겠습니다.
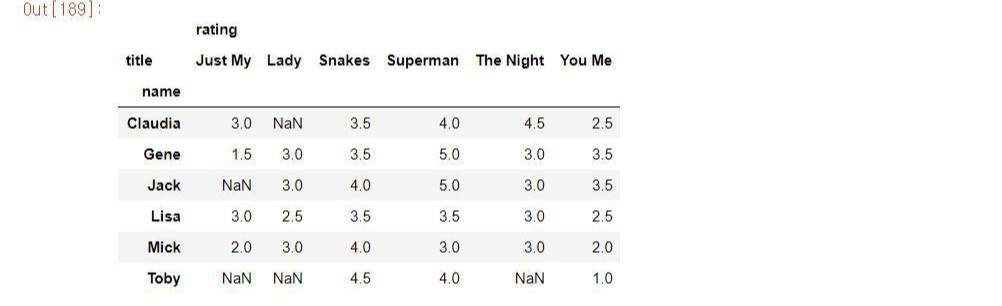
USER-MOVIE 행렬이 아래 있습니다. (출처: joyfuls.tistory.com/66님의 블로그 )
첫 째,
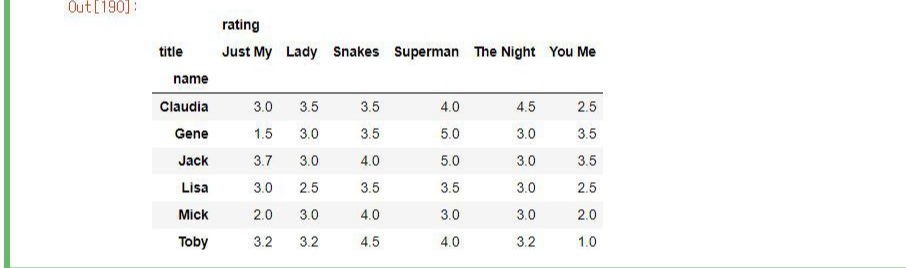
첫 번째 행렬에서 저희의 목표는 TOMY가 보지않은 영화들 Nan값들을 채워넣으려합니다.
두 번째 행렬은 USER별 평균값을 Nan에 채우기 위해 전치행렬을 구해준 모습입니다.
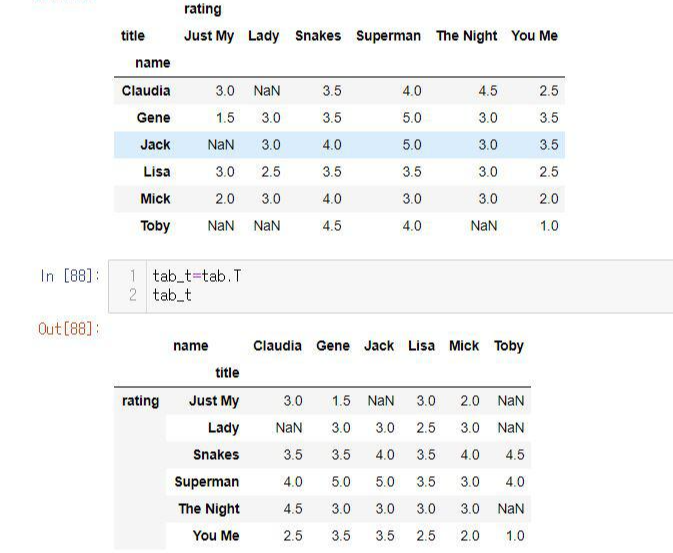
USER별 평균값을 채워주고 다시 USER-MOVIE로 바꿔준 모습.
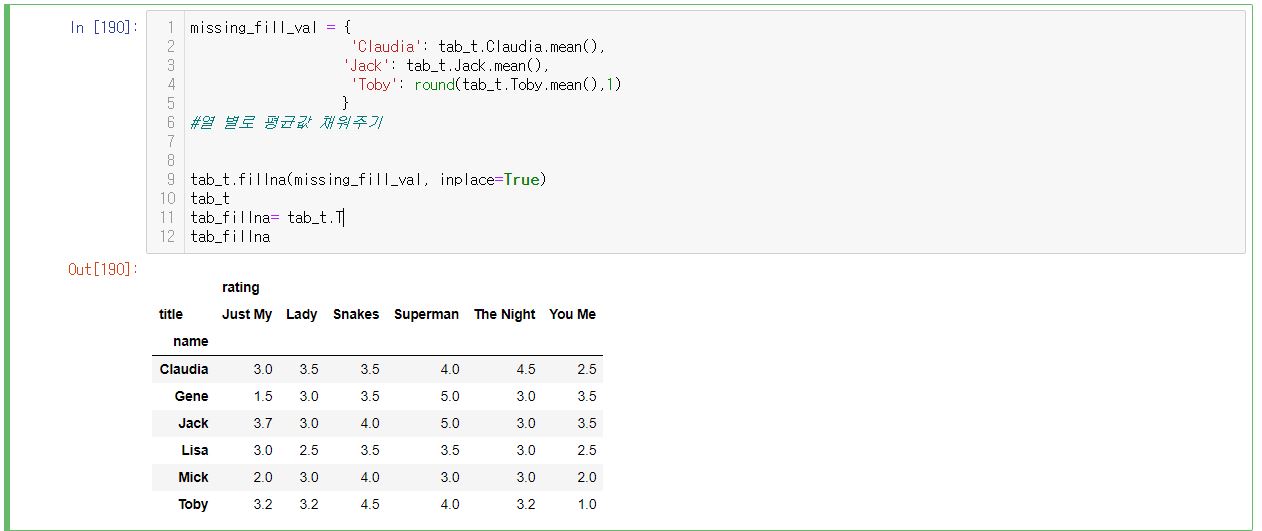
둘 째, SVD 수행( 단순 SVD )
SVD를 수행하여 구한 U , ∑ , Vt 함수를 다시 내적한 결과 본래 행렬과 같은 모습을 알 수 있습니다.
단 내적시, ∑는 리스트이기 때문에 diag 형태를 취하기 위해 np.diag를 이용합니다.
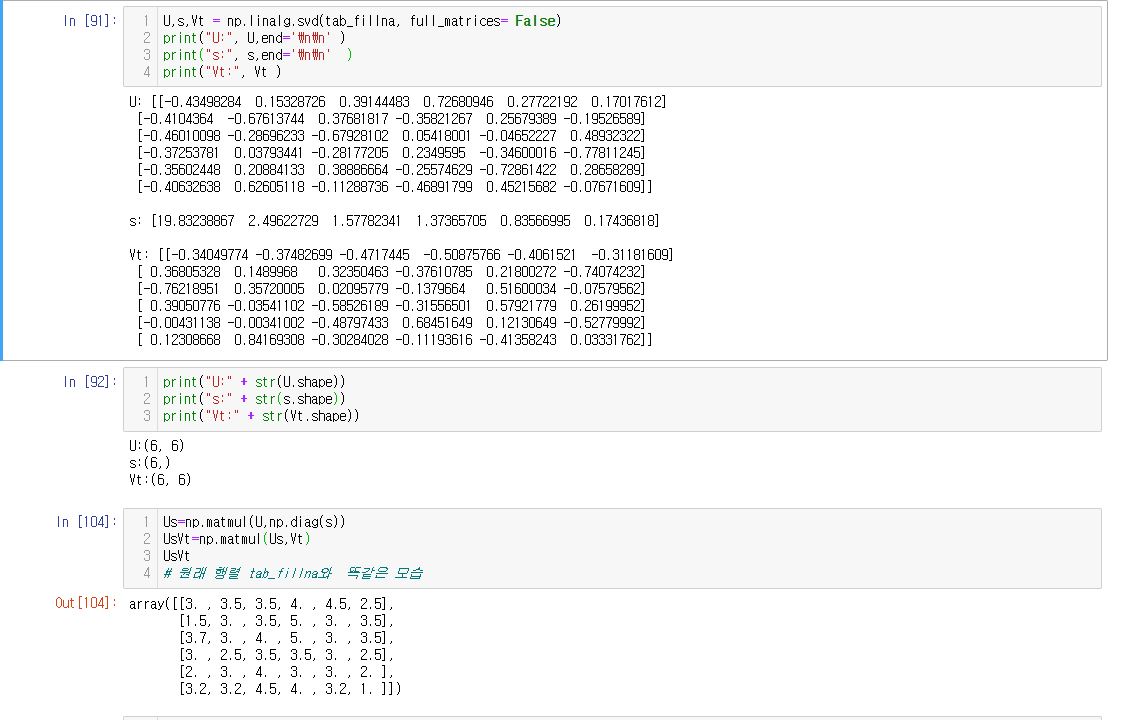
SVD가 잘 행렬분해 된 것을 봤으니 이번에 일부 요소 값만 사용한 Truncated SVD를 해보겠습니다.
6개의 특이값 중 3개를 사용해보겠습니다( n_components =3 )
둘 째, SVD 수행( n_components = 3 )
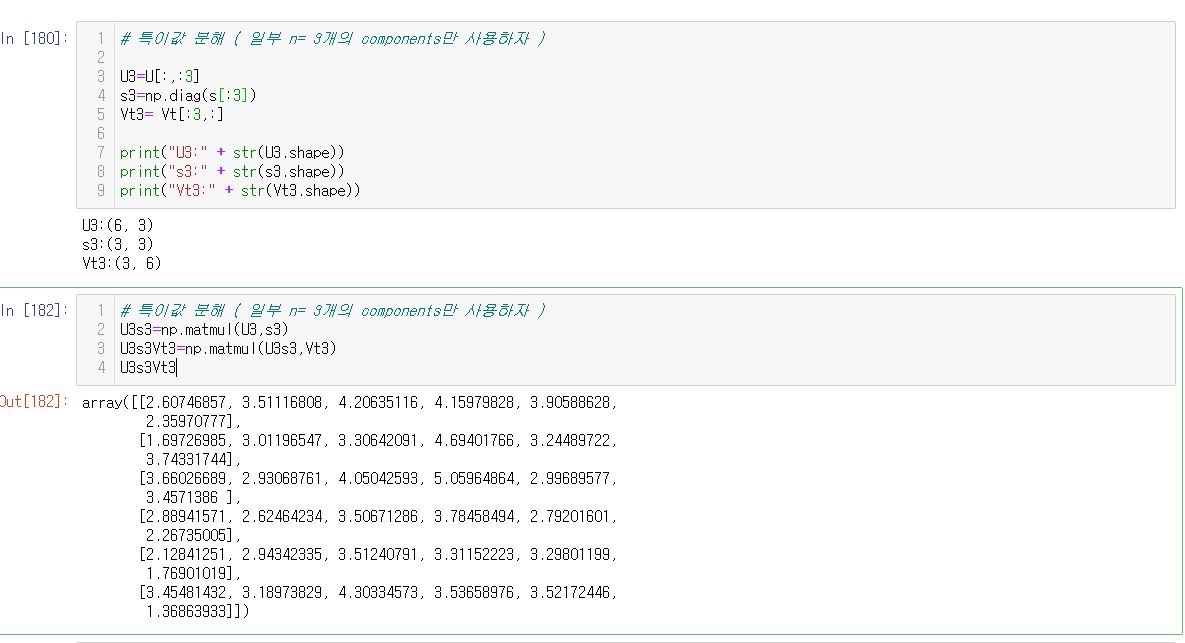
여기서 알 수 있는 점은 ∑뿐만 아니라 U 와 Vt 역시 n=3 만큼의 고유벡터를 사용하는 것입니다.(상위 3개)
때문에 위 그림을 보면 각 분해된 행렬의 shape이 U3은 (6,3) , ∑3은 (3,3) , Vt3 은(3,6) 인것을 알 수 있습니다.
다시 나중에 나눠진 행렬을 내적하면 U3s3Vt3 (6,6) shape의 형태가 나옵니다.
셋 째, 근사행렬 U3s3Vt3 와 본 행렬을 비교하기
자 이제 다왔습니다. 새로운 근사행렬를 DataFrame화 해준 행렬 B와 원래 USER별 평균치가 들어간 행렬 A를 비교해봅시다.
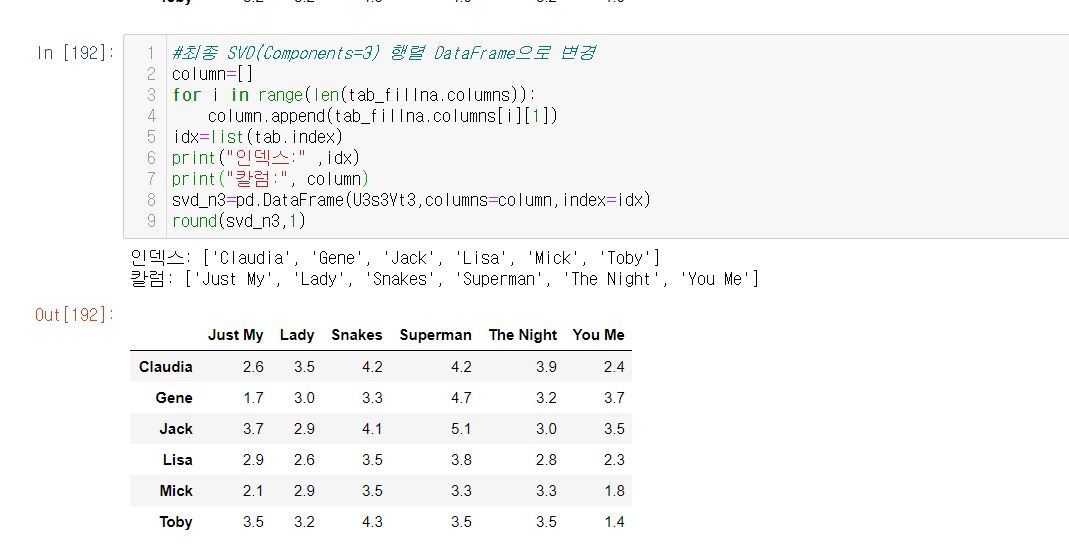
위 결과를 비교하면
행렬 A ) Toby가 보지 않은 영화 'JUST MY' ,'Lady', 'The Night' 가 처음 평균값의 rating은 3.2
행렬 B) Toby가 보지 않은 영화 'JUST MY'는 3.5 , 'Lady' 3.2 , 'The Night' 3.5 입니다.
즉 Toby에게는 영화 'Lady' 보다는 'JUST MY' 와 'The Night'를 추천해주는 것입니다.
자, 이로써 Numpy만 이용하여 SVD를 통한 간단한 추천시스템을 구현해보았습니다.
(원래는 scipy 나 sklearn , sunprise를 통해 더 정확하고 쉽게 구현할 수 있습니다)
단, SVD를 통한 추천시스템은 우리가 유저에게 아이템을 추천하는 이유를 정의할 수 없다는 단점이 있습니다.
'About Data > Recommender System' 카테고리의 다른 글
| NDCG - Normalized Discounted Cumulative Gain(평가지표) (1) | 2020.12.03 |
|---|---|
| if(kakao)2O2O - 개인화 콘텐츠 푸시 고도화 후기 정리 (0) | 2020.11.23 |

